
Enhancing scientific inference with evidence quality maps
Automated inference as a scalable engine of discovery

Science has always suffered from bottlenecks in information sharing and coordination. This is my attempt – building on my recent Evidence Quality Index (EQI) proposal – to induce a phase change in the effectiveness of scientific practices by building on innovations central to the modern internet. The plan begins with the birth of the World Wide Web.
In trying to meet the acute information coordination demands of the thousands of scientists at CERN in 1989, Tim Berners-Lee had the insight to combine multiple existing technologies. First was hypertext, which allowed in-context links between documents to aid with information finding and sharing. He then had the problem of how to easily write hypertext documents, leading him to combine hypertext with markup language – HTML. In combination with a new internet protocol and a browser to read and display HTML, the World Wide Web was born. It revolutionized how scientists communicate, with impacts extending far beyond science. The World Wide Web was not just a new tool but a platform for future possibilities in science.
Major bottlenecks remain. As a neuroscientist reading and contributing to the scientific literature it is clear that we can do much better. This can be illustrated by considering the kinds of challenges scientists face when going about the business of doing science.
When reading the scientific literature, it is difficult to determine 1) the methodological quality of a given study, 2) how much the study contributes evidence for its scientific claims, and 3) whether the study’s claims are supported by other studies. All of these problems are severely amplified when a study is outside one’s very specific area of expertise. This may be the major driver of hyper-specialization in science – one must specialize just to be able to make high quality inferences in science, and the larger and more complex the literature gets the more specialized we must be. This not only forces experts to cover more narrow topics over time but also limits interdisciplinary coordination and therefore reduces the originality and comprehensiveness of the work that gets done.
One of the original goals of the World Wide Web was to help with these kinds of problems. Ultimately, the Web is a graph structure with human-specified relations between documents. In principle, the right kind of relational graph with the right content could allow someone to follow links to learn whatever one needs to know to fully comprehend a new study. In practice, the Web does not provide the kind of structured relational graph needed to guide a scientist to rapidly understand a new study outside their area of expertise. Perhaps a different graph structure would help. It would also help to have a way to compress information implicit in scientific expertise to facilitate non-specialist inferences.
Substantial recent progress in knowledge graphs has made it possible to start converting the scientific literature into richly structured relational graphs. Continuing the thread originating with the Web, modern knowledge graphs evolved from Tim Berners-Lee’s 1999 attempt to augment the World Wide Web with rich semantic information (the Semantic Web). Knowledge graphs organize rich relational information among studies to facilitate meta-analytic insights into each study and the current state of understanding in a research area.
Yet these knowledge graphs do not incorporate scientific rigor, despite methodological and logical rigor being at the core of what makes a study scientific.
Recent progress has also occurred in quantifying scientific rigor, however. As a first pass, Wikipedia has emerged as a reliable knowledge resource. The general strategy has been to follow carefully curated rules, such as ranking information sources by reliability (peer reviewed journals > major news outlets > blogs). However, this depends on the assumption that a given source maintains its judgment quality across all cases. More crucially, Wikipedia lacks the granularity and level of rigor demanded of scientists making scientific inferences.
Closer to this level of detail and rigor is the GRADE (Grading of Recommendations Assessment, Development and Evaluation) system, which converts the features of clinical studies (typically via existing meta-analysis articles) into quantified assessment of evidence for a given clinical outcome. This approach has similarities with my ongoing efforts to create an Evidence Quality Index (EQI) that quantifies the quality of scientific results generally (not just for clinical applications). EQIs are multi-factor scores that quantify the methodological rigor of a given study, aiding rapid assessment of study quality.
Combining approaches to generate evidence quality maps (EQMs)
By analogy to Tim Berners-Lee combining existing approaches to transform scientific communication, I recently proposed combining two approaches to compose a new platform for science discovery: knowledge graphs of scientific studies augmented by quantification of scientific rigor.
These evidence quality maps (EQMs) would, in principle, allow for 1) rapid assessment of a study’s quality, 2) how the study’s conclusions relate to other studies, and 3) how much the study uniquely contributed to supporting its scientific claims.
What do EQMs consist of? They are graphs with nodes and links. First within a EQM are scientific claim nodes, such as [“Neural activity in primary motor cortex causes body movement”]. Next, there are study nodes, such as [Fritsch & Hitzig, 1870] and [Barker, Jalinous, and Freeston (1985)]. Most essentially, there are links from study nodes to claim nodes, quantifying the amount of evidence for/against the claim that each study provides. We might see [Fritsch & Hitzig, 1870] and [Barker, Jalinous, and pFreeston (1985)] both link to [“Neural activity in primary motor cortex causes body movement”], indicating those two studies provide evidence for or against that scientific claim.
Finally, there is extensive EQI information quantifying and contextualizing each link, allowing for rich scientific inferences and revision of inferences based on future research. For instance, the [Fritsch & Hitzig, 1870] link would indicate that electrical stimulation in canine primary motor cortex causes body twitches, while the [Barker, Jalinous, and Freeston (1985)] link indicates that noninvasive electrical stimulation (with transcranial magnetic stimulation) in human primary motor cortex causes finger movements. This graph organization makes it easy to see cross-study convergence and study-specific inferential details regarding a scientific claim.
The core of EQMs: An updated evidence quality index (EQI)
As part of my recent EQM-based improvements on my first version of EQIs, I proposed the following multi-score system. Each EQI score is designed to facilitate, respectively, 1) rapid assessment of a study’s methodological quality, 2) how the study’s conclusions relate to other studies, and 3) how much the study uniquely contributed to supporting its scientific claims.
EQI-M (evidence quality index - methods): The study’s methodological quality. Specifically, the likelihood that a study’s results would replicate (reliability), and whether its claims are appropriate given the methods used (validity). For example, a randomized controlled trial would receive a higher EQI-M score for a causal inference than a correlational study.
EQI-E (evidence quality index - evidence): How the study’s conclusions relate to other studies. Specifically, the overall Bayesian evidence that a study’s scientific claims are true given the current study’s EQI-M-weighted results, conditioned on the prior probability of those claims being true based on the rest of the literature. This quantity depends on inter-node inferences within the EQM, with convergence of studies on scientific claim nodes being quantified into EQI-E scores.
EQI-C (evidence quality index - contribution): How much the study uniquely contributed to supporting its scientific claims. Specifically, the contribution of a study to changing its claims’ EQI-E scores. If a study fills a genuine knowledge gap then its EQI-C score will be large, even if its EQI-M score is relatively low. The EQI-C score could also be high if a study is a well-powered and rigorous replication of a prior study with a low EQI-M score, as it could bring conclusive evidence to an area of high uncertainty. In contrast, if a study is a high-quality repeated replication (scoring well on EQI-M and EQI-E) it would not receive a high EQI-C, as it was confirmatory and provided little to the study’s claims’ EQI-E scores.
Each EQI score (and subscore) ranges from 0 to 100. A study’s EQI scores are updated annually, such that a study’s EQI(0) is a snapshot of its EQI at publication, EQI(1) reflects its EQI a year after publication, and so on.
Updating EQI scores will be essential for the intended experience for readers of the scientific literature: The presented EQI scores should reflect current knowledge regarding the quality of the inferences present in each study. This also presents scientific authors with an opportunity: Later improved validation of their methods could retroactively increase the EQI-M scores of their prior studies, while replication of their prior results could retroactively increase the EQI-E scores of their prior studies’ claims. I expect that updating EQI scores will increase incentives for building cumulative and rigorous lines of scientific evidence.
Why build evidence quality maps now?
EQMs are timely both on the demand side and the supply side.
On the demand side is the urgent need to save the scientific peer review system. There is increasing recognition that peer reviewers are overburdened by the ever-growing scientific literature and the increasing level of specialized expertise needed to properly evaluate each study. Moreover, there is increasing dissatisfaction with the existing scientific journal system as scientists must pay for publication yet do not get paid when exerting effort to support the publication process through peer review.
I hypothesize that EQIs will be a boon to peer reviewers, allowing rapid assessment of study quality. As the EQI system improves, peer reviewers may increasingly shift from full evaluators to endorsers of EQI-based study quality assessments. This will, in turn, reduce the bottleneck of peer review on scientists’ time and the scientific literature.
On the supply side – what makes EQIs and EQMs possible now – is the recent availability of large language models (LLMs) and other machine learning tools for automated semantic processing of the scientific literature.
This contrasts with Berners-Lee’s Semantic Web attempt two decades ago, as well as Wikipedia’s predecessor Nupedia. Nupedia had a seven-step peer review process to control the evidence quality of articles before being posted. Unfortunately, this did not scale: while Nupedia had 21 articles in the first year, Wikipedia had 18,000 articles in its first year. The evidence quality process was too burdensome for Nupedia to scale, mostly because of the need for extensive time demands of experts to implement peer review.
In contrast to these efforts, I hypothesize that the availability of modern LLMs now makes EQMs possible and scalable for the first time. EQMs will utilize EQIs to automate the most effortful aspects of peer review via machine learning and LLMs. EQMs will also not require authors to write new articles; they will use existing and new preprint and peer-reviewed articles written and published outside the EQM system. This process is expected to yield scalable knowledge maps of scientific publications with link quality quantified in terms of evidence quality, improving the accessibility of scientific studies, scientific study searches, and scientific inferences.
No doubt there are several challenges to overcome before we can create useful EQMs, however.
For instance, there is the problem of LLM hallucinations, wherein models fabricate information inappropriately. I hypothesize that EQMs will help reduce LLM hallucinations, however. This follows from EQMs requiring formal rules for map updating, constraining LLMs more fully in their use of evidence-based logic, likely keeping them from the faulty logic and lack of evidence driving hallucinations. Further, the use of a map external to a given LLM leaves the LLM’s logic open to scrutiny by other LLMs and humans, allowing for error-correcting feedback loops when constructing and using EQMs.
Many potential map generation problems will be addressed via error correction feedback loops. First is the core of the EQI-M training algorithm: optimize prediction of reliability of a given study’s results based on the methods it used. This is expected to reduce errors as more training data are incorporated. Second is model training using historical scientific publications that domain experts know well, allowing rapid assessment and feedback (from any one domain expert) to help calibrate the EQM-generation algorithms in each domain. Existing systematic review and meta-analysis publications will provide important training data as well, as these high-level assessments overlap with the inferences EQMs are designed to help automate. Third is use of EQMs to aid with peer review, such that peer reviewers can (with little or no effort) provide feedback to improve EQMs. Indeed, in many cases we can require no additional effort from peer reviewers, as we can use the thousands of existing pubic peer reviews as training data, with reviewer-identified issues used as evidence quality signals during EQI training.
If LLMs are essential to the scalability of EQIs, why not just use LLMs without maps? For the same reason that explorers have always created maps: To track where they’ve been, to plan where to go next (e.g., based on gaps in the map), and to have a common representational substrate to record, share, and cumulatively improve knowledge. I expect that these properties of maps will enable EQMs to facilitate grounding of LLM inferences in empirical constraints, improving LLM-based inferences (e.g., reducing hallucinations) when constrained by EQM-based inferences (e.g., calculating an EQI-M estimate for a study or inferring which studies provide evidence for/against a scientific claim).
Next steps toward EQMs
This proposal is clearly ambitious, given that two successful visionaries – Tim Berners-Lee and Jimmy Wales – were unable to scale similar ideas. Yet the goal they were pursuing is more than worth the effort: a major upgrade in scientific information representation, in the form of a map of easily navigable scientific information optimized for high-quality scientific inferences.
What’s different now is the availability of LLMs, which can automate the extraction of scientific claims, methods, and logic from scientific publications and curate them into a knowledge graph. LLMs will also be essential for applying EQI scores to each publication – the core of the EQM approach. This is due to the need for semantic interpretation of scientific article text to aggregate information across studies, such as whether the same methods were used across studies and whether those methods were used to address the same or different scientific claim. These are nontrivial challenges when it comes to scaling a knowledge graph to entire scientific literatures, but I hypothesize that use of LLMs along with the error correction feedback loops identified above will overcome these challenges to yield a scalable EQM generation system.
As a very rough demonstration of the EQI/EQM framework, I used an LLM to generate an interactive EQM of my own lab’s work related to brain activity flow. (This builds on the interactive figure in my prior EQI/EQM post). I chose these 17 related papers because they support both overlapping and divergent scientific claims, use several distinct methods, and (because they’re my own studies) I could easily evaluate the validity of the EQM inferences. This was highly automated, with only two LLM prompts instructing the LLM to read this post, read my prior EQI proposals, and read the PDFs for the 17 included studies. I asked the LLM to take shortcuts where necessary (e.g., it did not calculate Bayesian evidence for the EQI-E scores) for this demo. You can see the interactive demo here: Activity flow EQM interactive figure.
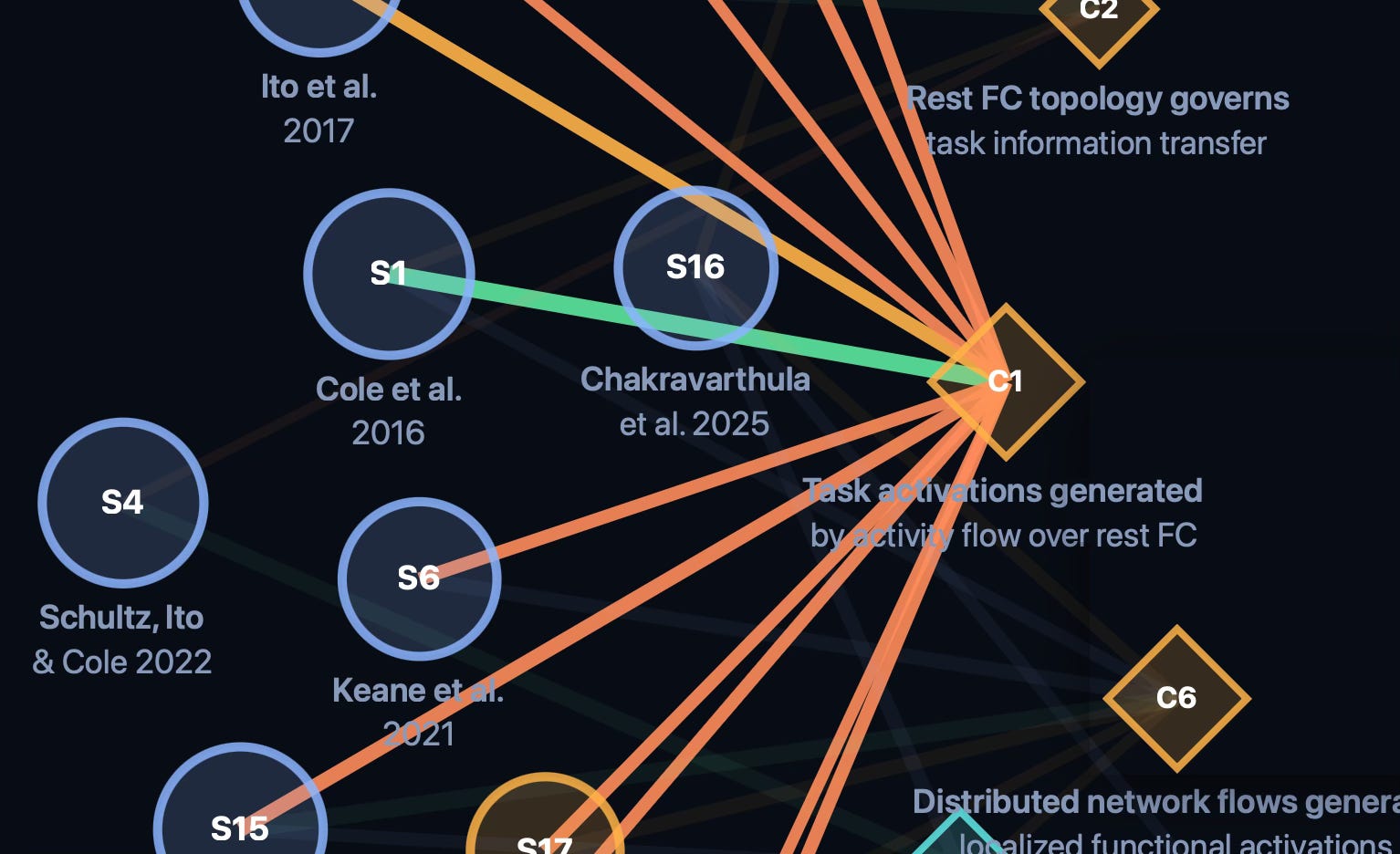
While I’ve emphasized automation here, developing the initial EQM generation system will require human effort – effort that will be well worth it. Who doesn’t want a score that immediately signals how much evidence a study likely provides for/against a scientific claim before reading it? What peer reviewer wouldn’t like assistance with identifying likely methodological issues in a study as they are doing their own assessment?
I expect – like Tim Berners-Lee’s 1989 Web proposal – that the ideas shared here will have an impact well beyond scientific practices. This is because science is humanity’s best access to empirical reality, and improving access to that reality would benefit all manner of inferences in daily life and beyond. This logic extends to scientists themselves, as we are essentially non-scientists when it comes to inferences outside our narrow area of expertise. From climate change to vaccines to nutrition, I would love to have well-calibrated EQMs to facilitate the many science-related decisions I need to make for myself and my family.
We’re looking for volunteers to help develop EQIs and EQMs. If you’re interested, please say so in the comments (or email me). We will be developing EQIs and EQMs as open access for scientists and the public, for the betterment of human knowledge.
Imagine a world in which a detailed map of all scientific knowledge were given to every single person on the planet. That’s what we’re building.